Product Highlights

Lifecycle Management
Provides end-to-end model management—from selection and deployment to monitoring and continuous optimization—supporting the full workflow from development to production for efficient iteration and operations.

Flexible Deployment
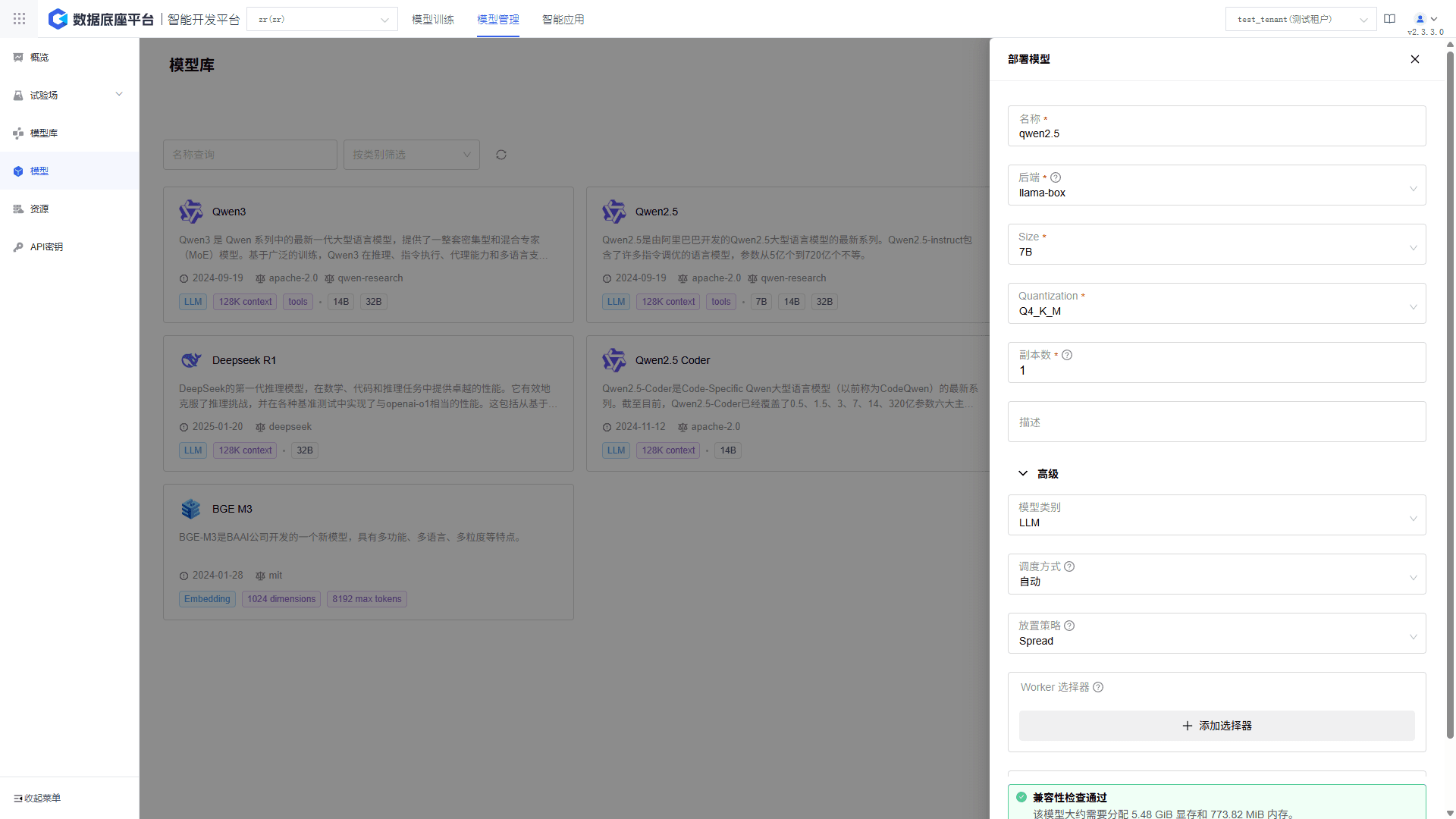
Supports quick selection from built-in model libraries or local model uploads, with adjustable deployment parameters and instance configurations to meet diverse business needs.

Panoramic Monitoring
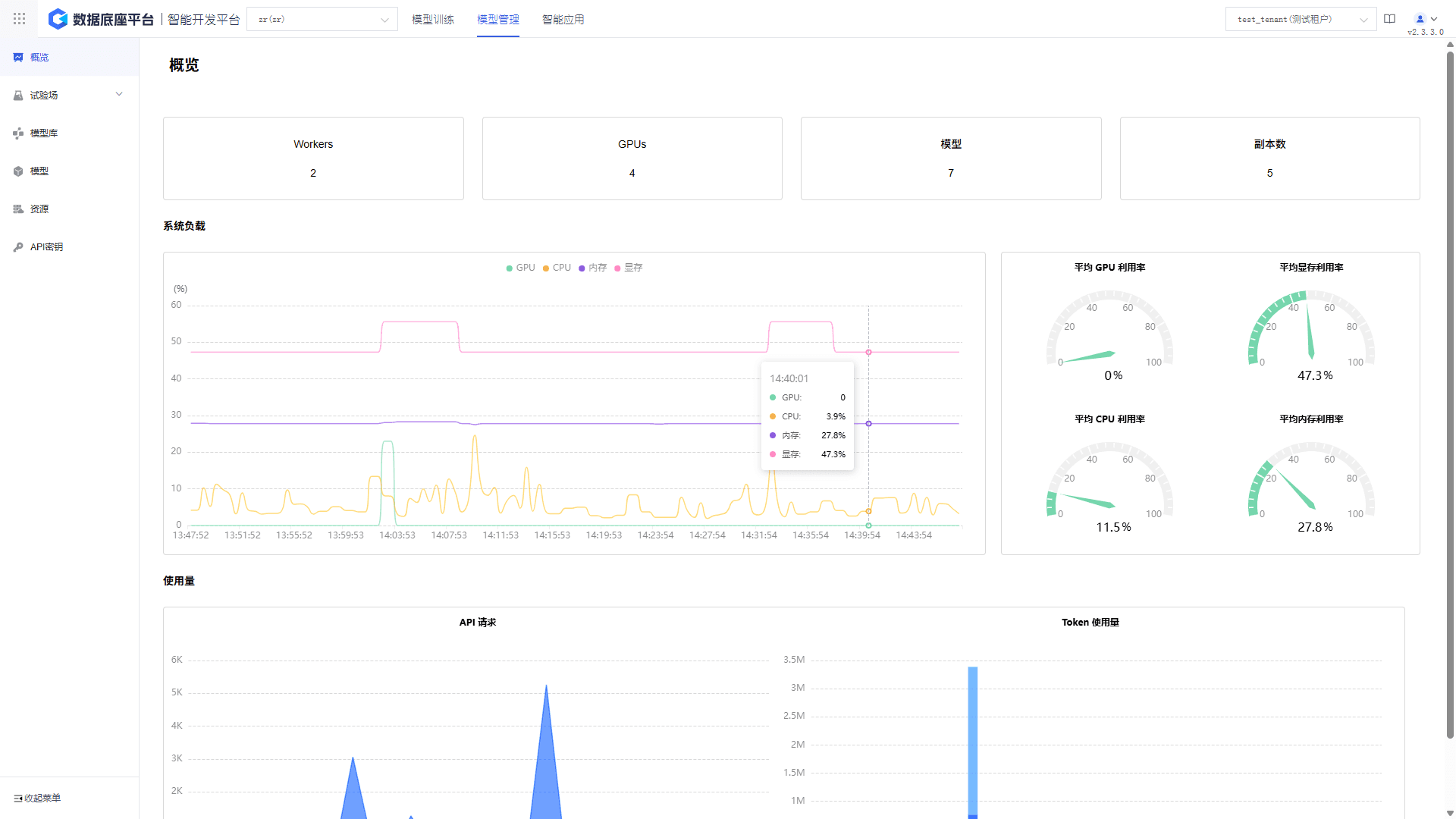
Visualizes key metrics such as system load, API calls, and response latency in real time, offering multi-dimensional analytics to support operational decisions and performance optimization.

Real-Time Instance Control
Enables start, stop, delete, and dynamic scaling of model instances, supporting multi-replica deployment and load balancing to ensure high availability.

Multi-Modal Validation
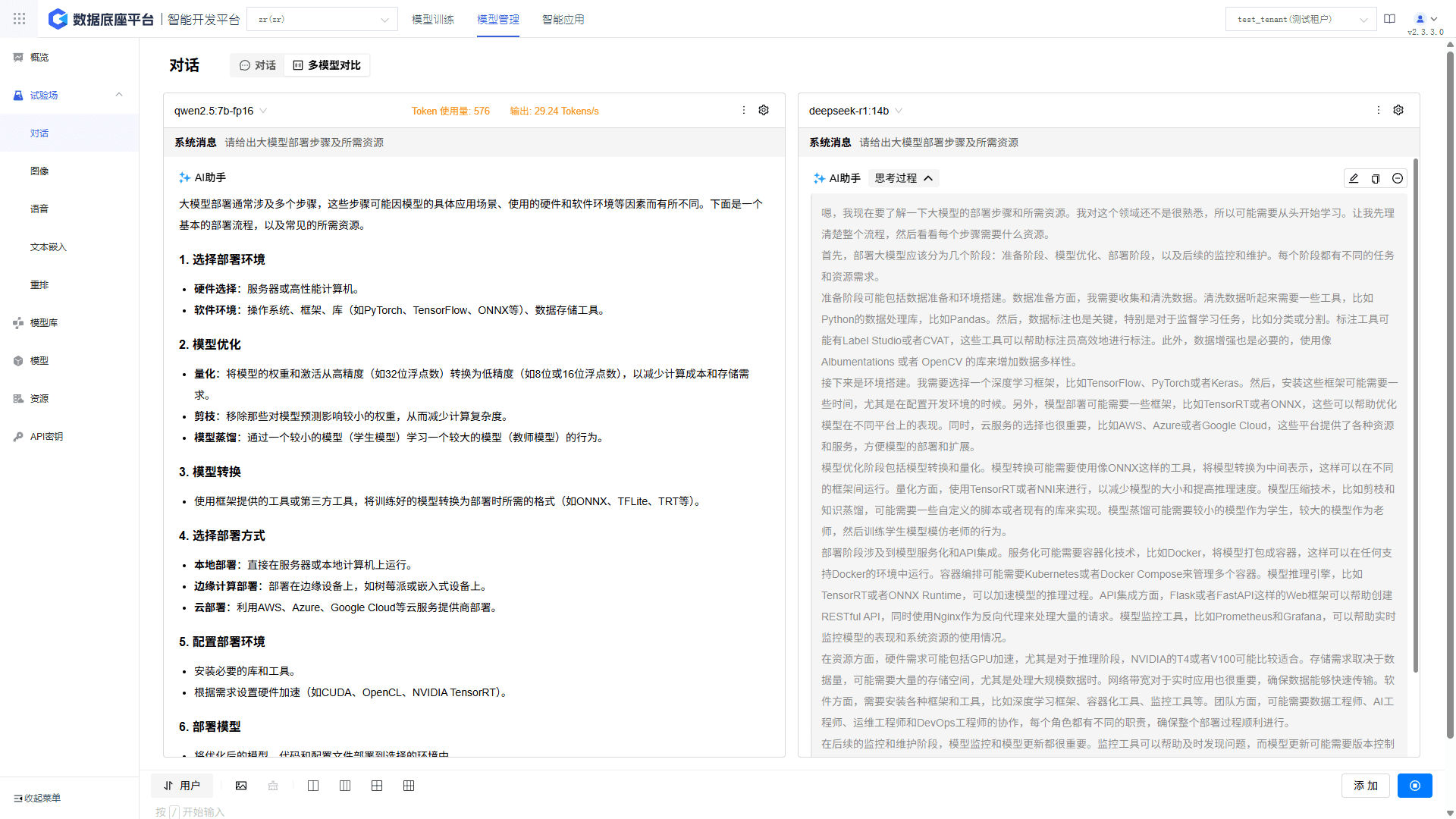
Integrates testing across dialogue, image, and speech scenarios, providing parameter tuning and model comparison tools to accelerate validation and optimization.

Intelligent Resource Scheduling
Fine-grained management of worker nodes, GPU resources, and model files, with dynamic monitoring and intelligent allocation to maximize compute efficiency.
Key Features
 Modal Management
Modal Management Real-Time Monitoring
Real-Time Monitoring Model Validation
Model Validation
End-to-end lifecycle management covering selection, deployment, monitoring, and optimization. Supports metadata labeling and quick retrieval for traceable, reusable models.
Captures performance metrics, resource usage, and API calls with visual dashboards. Alerts and log tracking ensure service stability.
Validates models in dialogue, image, and speech scenarios. Supports hyperparameter tuning, A/B testing, and visual performance comparisons for fast optimization.
Application Scenario

Full-Stack Model Management
Offers end-to-end services from development to deployment, supporting full-lifecycle management of multimodal models. Intelligent scheduling optimizes resources, real-time monitoring ensures stability, and robust security lowers the barrier to AI adoption, helping enterprises accelerate intelligent transformation.
Build Your AI-Native Data & AI Platform with KeenData