Product Highlights

Full Training Pipeline
Supports the full training lifecycle—from (incremental) pre-training and multimodal instruction tuning to RLHF (Reward Modeling, PPO/DPO/KTO, etc.)—designed to meet diverse business and industry needs.

Efficient Fine-Tuning
With parameter-efficient approaches like LoRA, significantly reduces parameter size and computational/storage costs, achieving the right balance between model performance and resource consumption.

Alignment Optimization
Provides fine-grained RLHF configuration combined with multiple optimization algorithms, ensuring outputs are aligned with human values and specific business requirements.

Low-Code Compatibility
Zero-code AutoML workflow, fully compatible with mainstream model architectures and domestic chips, offering both technical depth and ease of use.

Automated Dataset Distillation
Enables fully automated dataset distillation by constructing domain taxonomies, generating domain-specific questions, and leveraging large models to create high-quality answers and reasoning processes—helping enterprises efficiently prepare training data.

Unified Data Management
Delivers advanced dataset generation features (e.g., document-based Q&A), with centralized dataset management that allows users to view, edit, and maintain all generated content.
Key Features
 Visualized Fine-Tuning
Visualized Fine-Tuning Model Evaluation
Model Evaluation Inference Debugging
Inference Debugging Diverse Training Algorithms
Diverse Training Algorithms
Provides an intuitive interface for configuring fine-tuning parameters, supporting the full workflow of training, evaluation, inference, and model export.
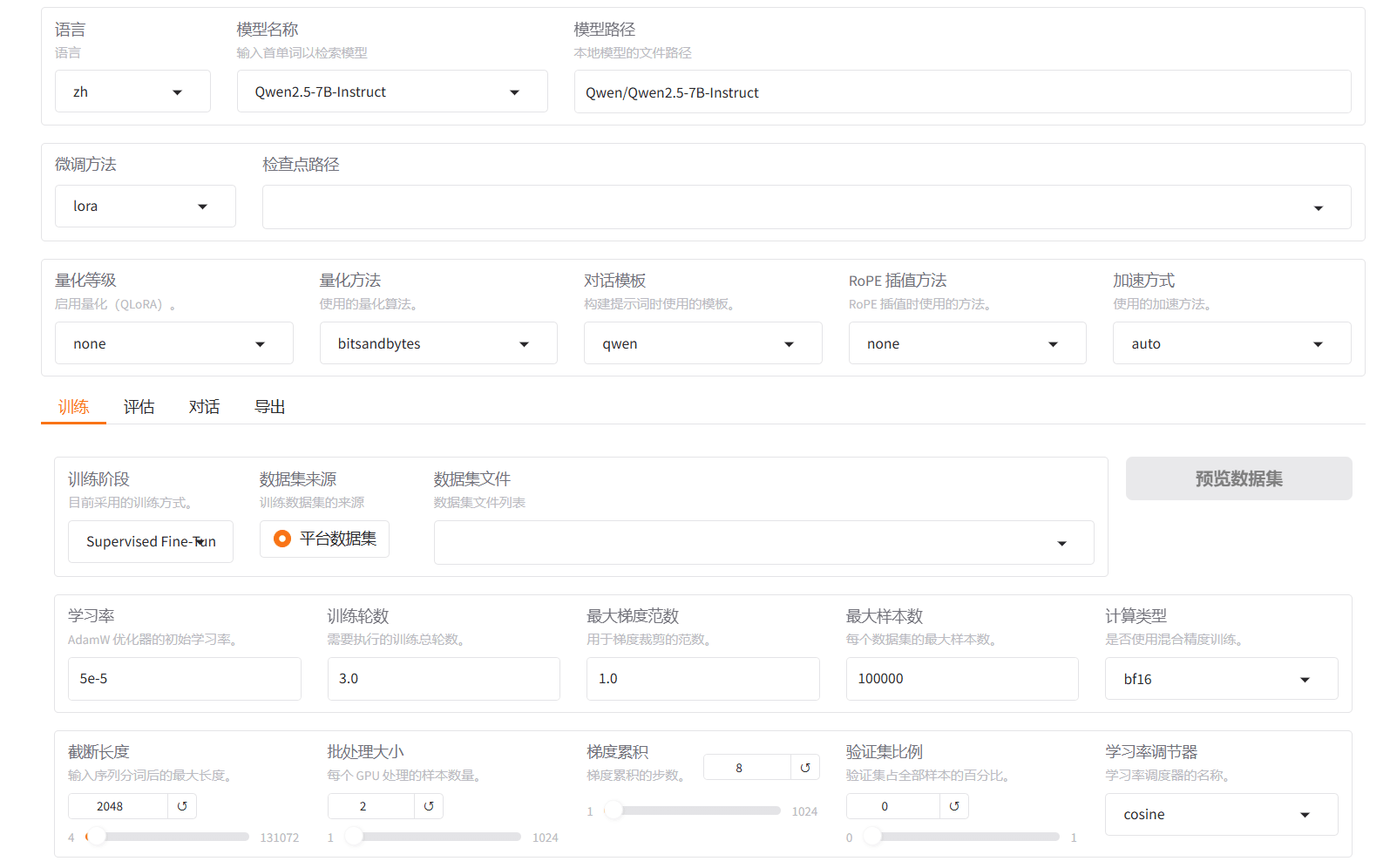
Enables evaluation of trained models with validation datasets, with configurable parameters such as truncation length, max samples, and batch size.
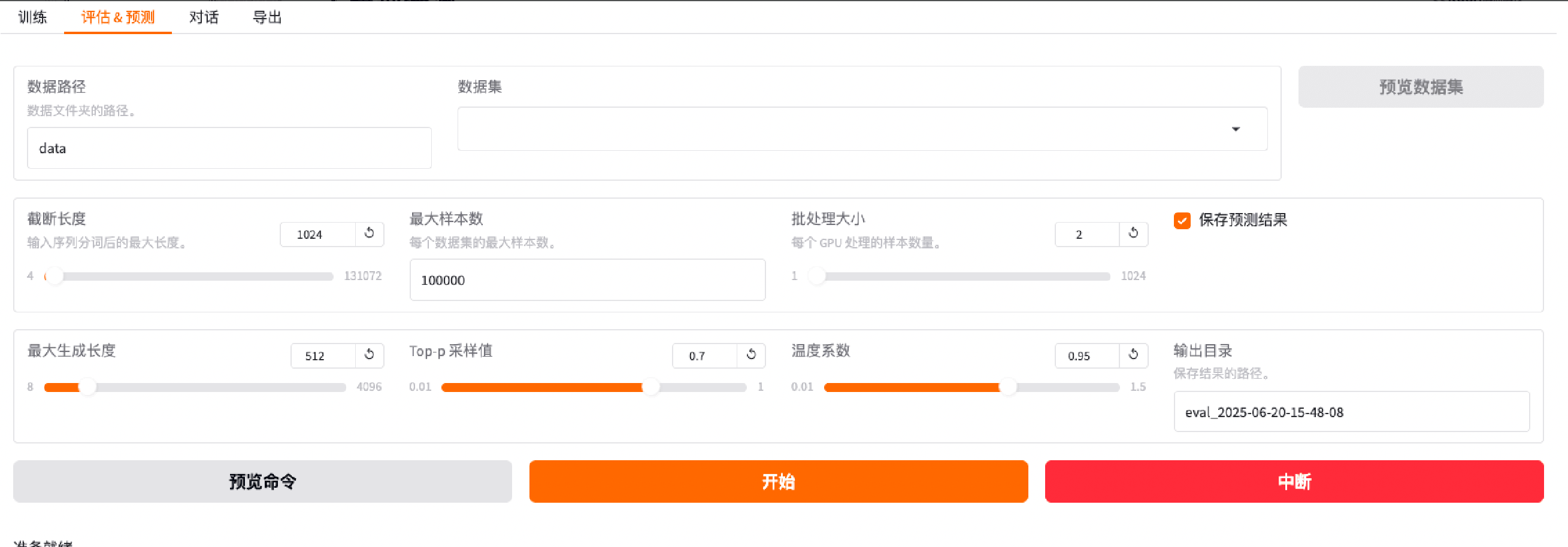
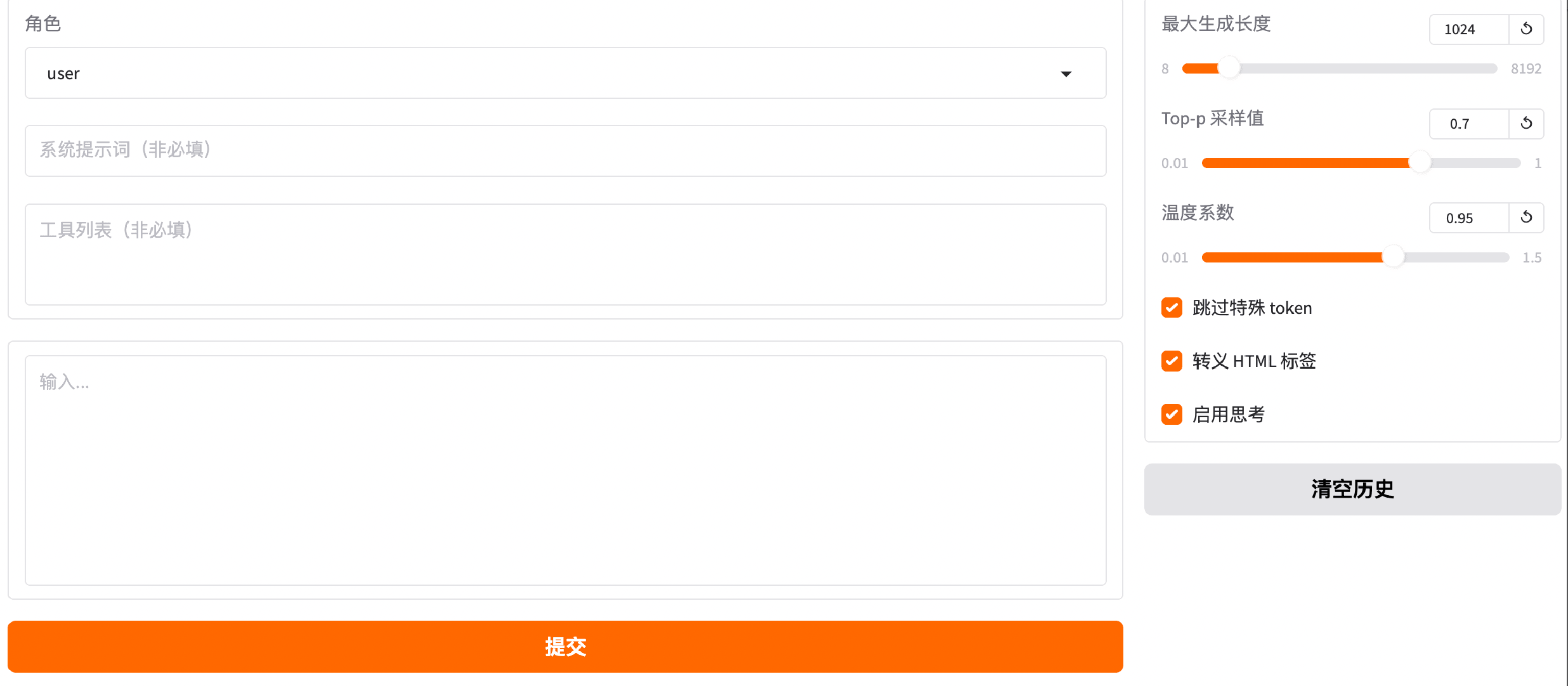
Supports inference testing with multiple configurable parameters, including max generation length, Top-p sampling, temperature, skip special tokens, escape HTML tags, and enabling reasoning.
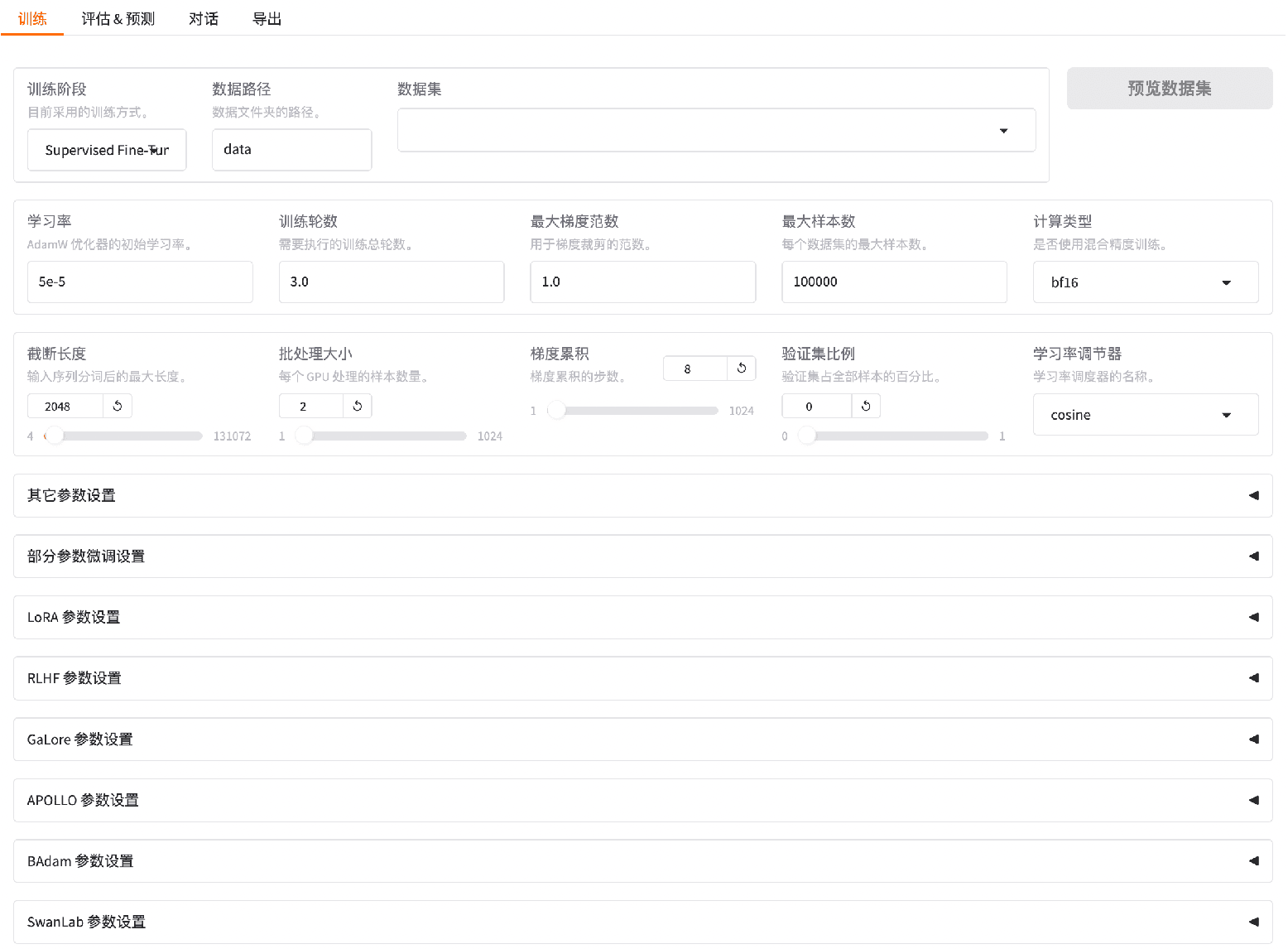
Supports a wide range of algorithms, including (incremental) pre-training, (multimodal) instruction fine-tuning, reward modeling, PPO, DPO, and KTO training.
Application Scenarios

Specialized Vertical Tasks
In domains with high data barriers—such as legal document generation and drug molecule design—knowledge systems and terminology are highly specialized. General-purpose models often struggle to accurately understand or generate such content. Fine-tuning helps boost model performance on these domain-specific tasks.

High-Stability Requirements
For mission-critical scenarios requiring highly stable outputs—such as equipment fault diagnosis or code generation—the accuracy and consistency of model outputs directly impact system reliability and safety. Fine-tuning ensures models adapt better to specific tasks, reducing errors and improving stability.

Sensitive Data & Private Deployment
In scenarios involving sensitive data, such as government document processing or banking compliance review, strict requirements on security and privacy apply. Fine-tuning models in local environments meets customization needs while ensuring data remains secure and private.
Build Your AI-Native Data & AI Platform with KeenData